Spark Structured Streaming
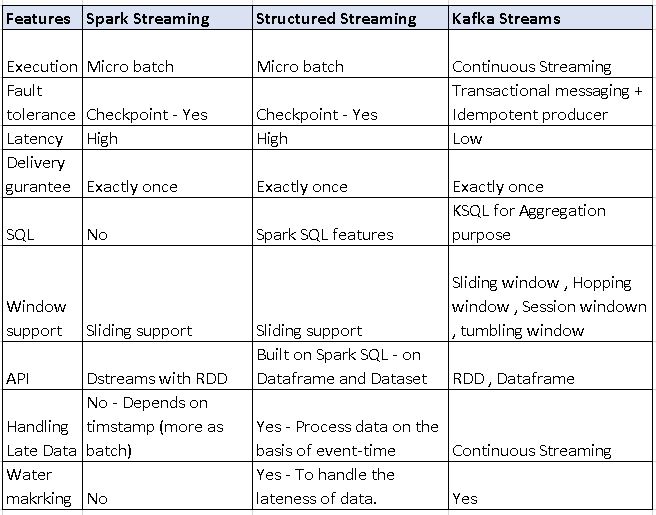
Comparison of Spark streaming , Structured streaming and Kafka Streams
What is a Watermark?
Its a method to handle the lateness. Basically , it can be regarded as threshold to specify how long system wait before data arrives. If the event falls under the watermark interval , then the event’s data is utilized for computation else the event’s data is dropped for that time interval.
Unsupported Operations in Structured Spark streaming
- Multiple streaming aggregations are not yet supported on streaming Datasets.
- Limit and take the first N rows are not supported on streaming Datasets.
- Distinct operations on streaming Datasets
- Sorting operations are supported on streaming Datasets only after an aggregation and in Complete Output Mode.
- Few types of outer joins on streaming Datasets are not supported. List is here
Details and credits are here
Sample code on Stuctured Spark Streaming (Apache site)
spark = SparkSession. ...
# Read text from socket
socketDF = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
socketDF.isStreaming() # Returns True for DataFrames that have streaming sources
socketDF.printSchema()
# Read all the csv files written atomically in a directory
userSchema = StructType().add("name", "string").add("age", "integer")
csvDF = spark \
.readStream \
.option("sep", ";") \
.schema(userSchema) \
.csv("/path/to/directory") # Equivalent to format("csv").load("/path/to/directory")