AWS : PySpark on EMR Cluster
14 Simple Steps to execute PySpark code on AWS EMR
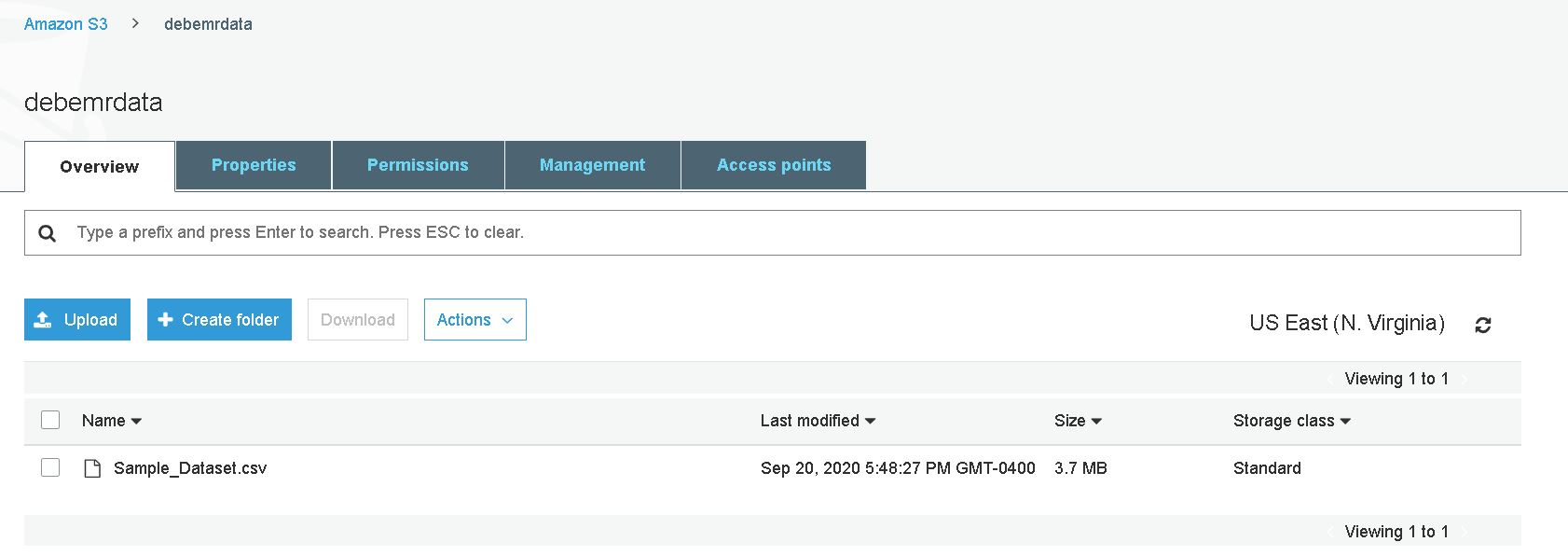
1. Upload sample data on S3
2. Create EC2 Key Pair
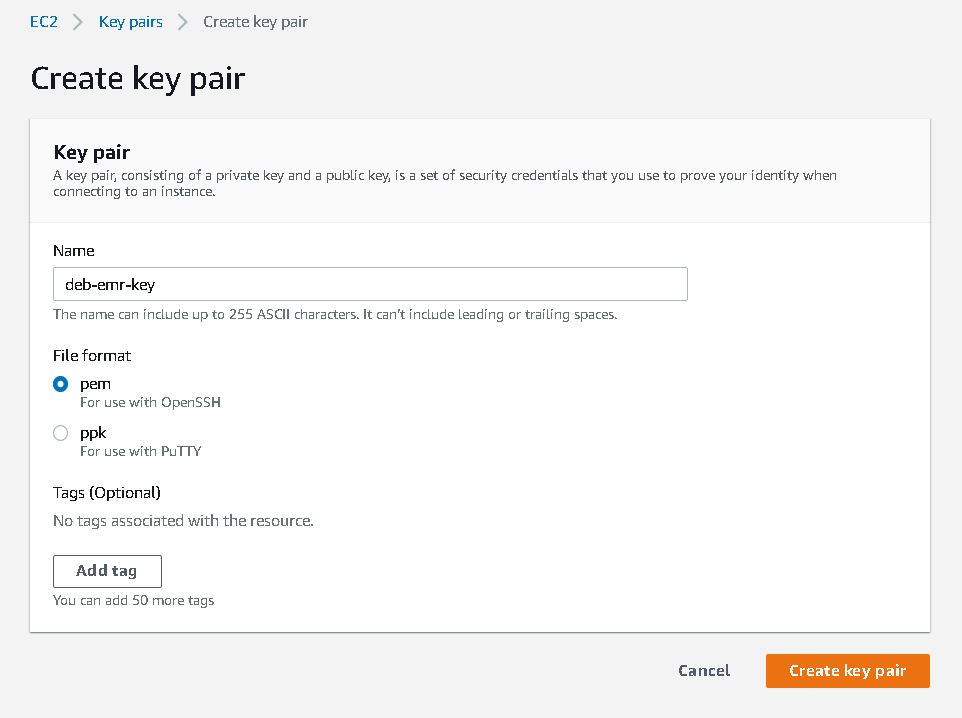
3. Create PEM file which can be used creating EMR cluster
4. Next Create EMR Cluster

5. Use EC2 Key pair and core hadoop to create EMR cluster
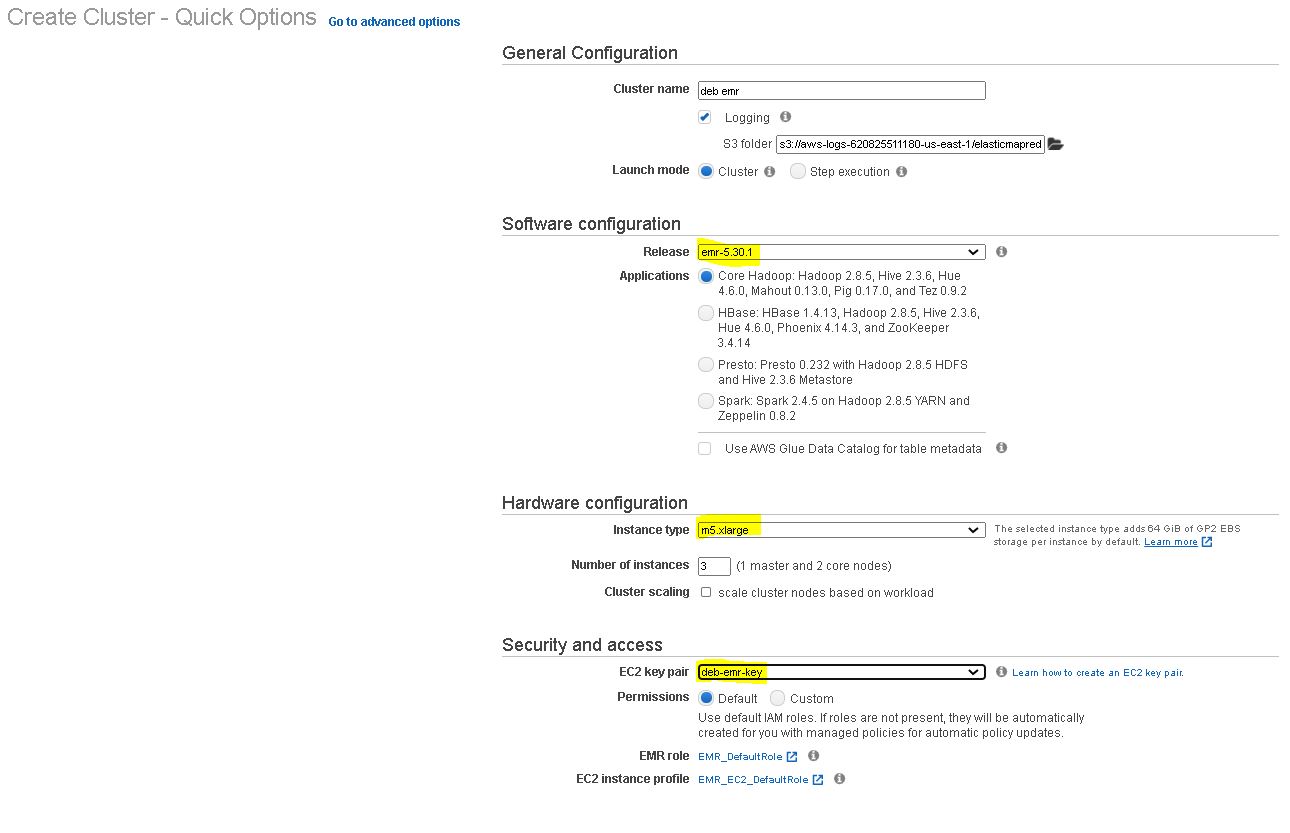
6. Check the Advance settings and add Hadoop components to cluster
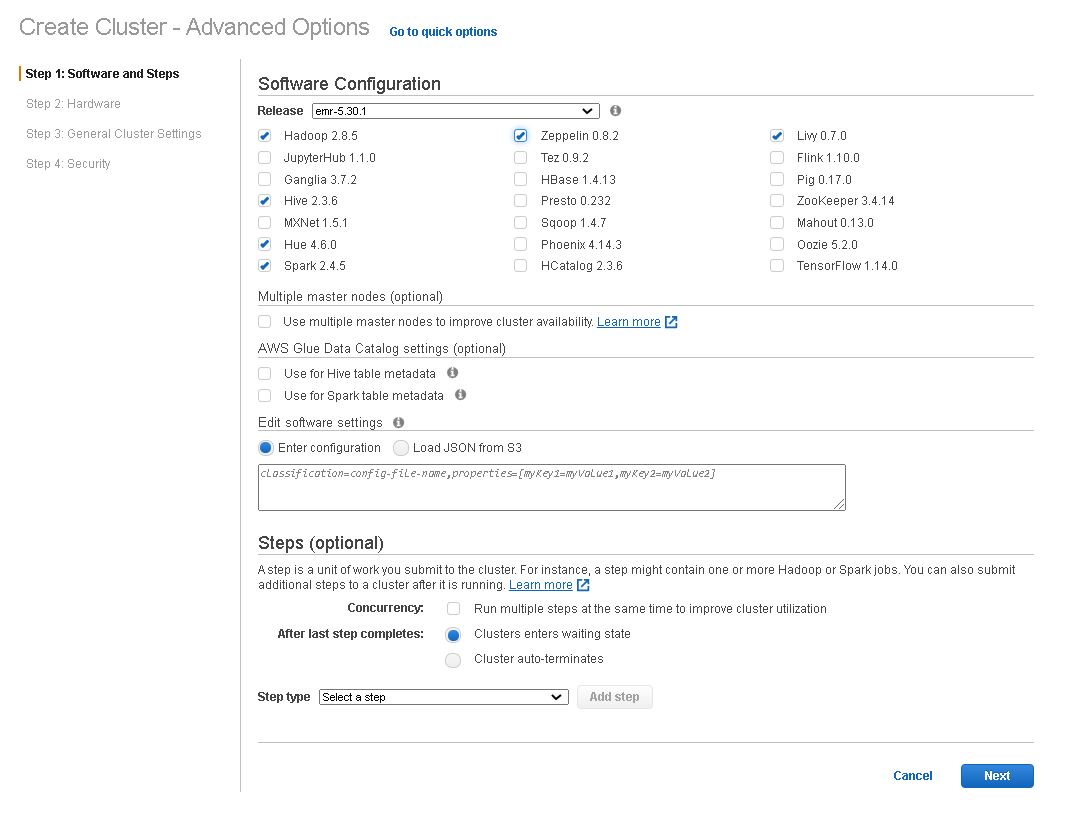
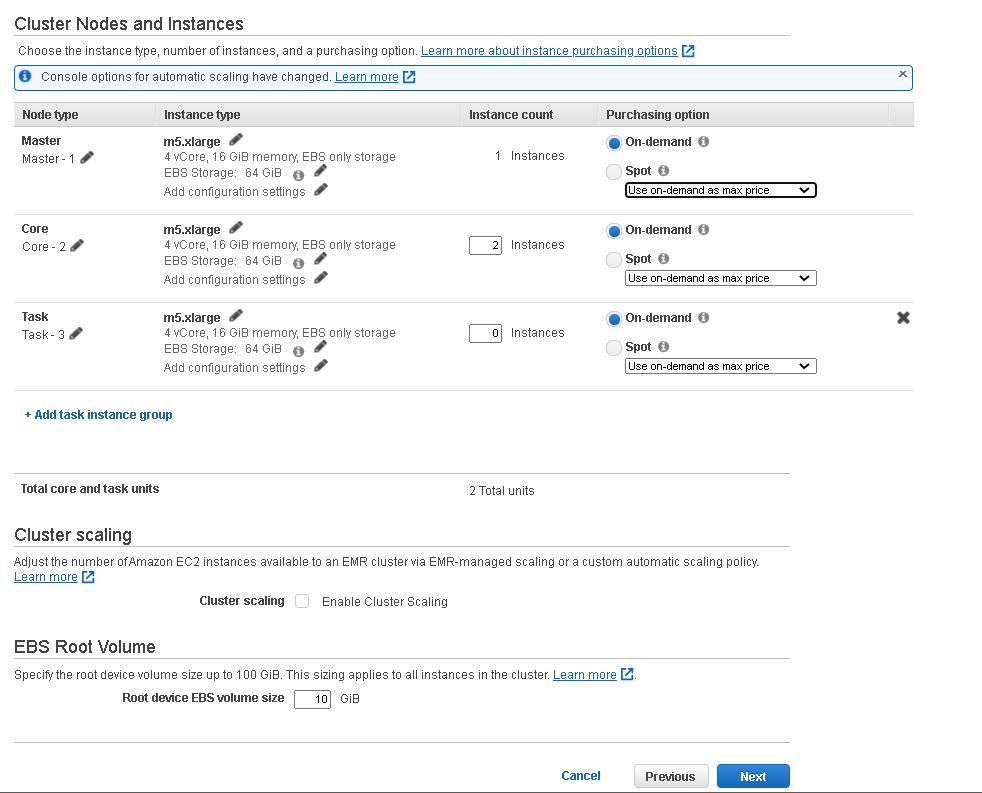
7. Update the size, type of instances and size of EBS
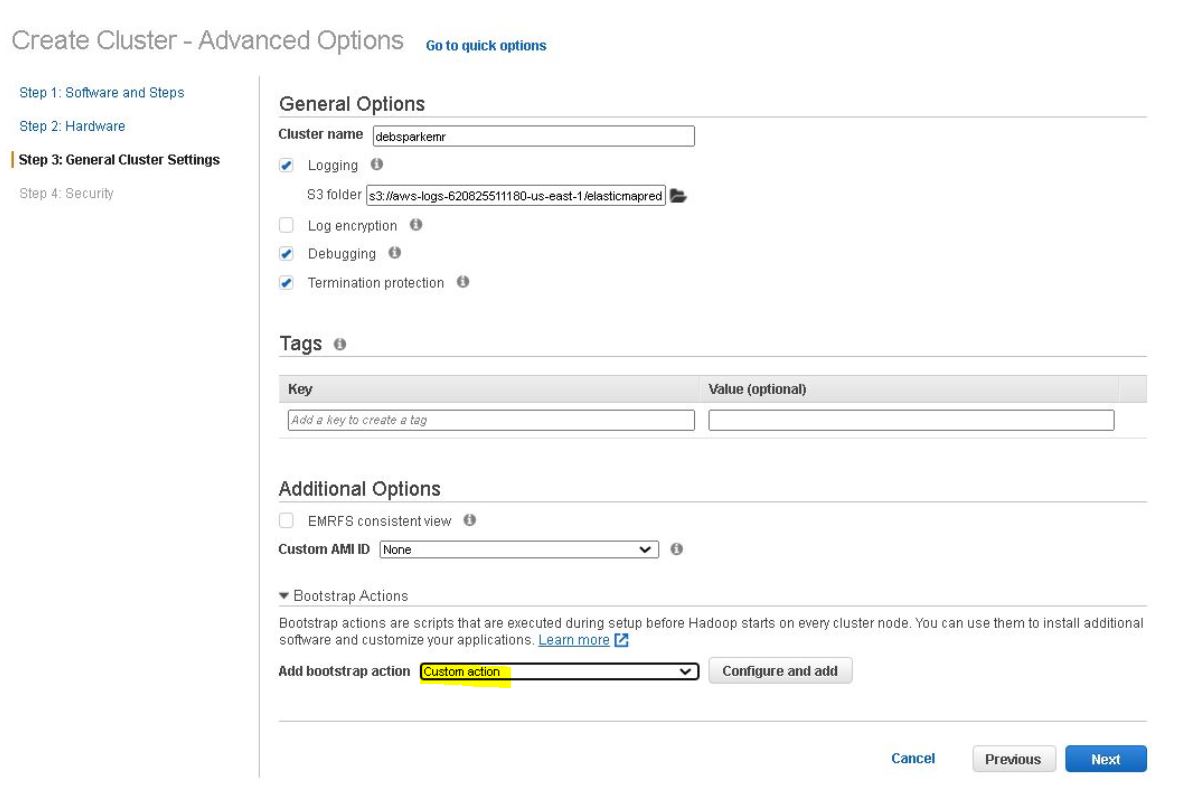
8. Users can add Bootstrap code
- Bootstrap code can help you install external libraries for Python , Hadoop , Spark , etc.
- Write small code (shell) to perform small tasks
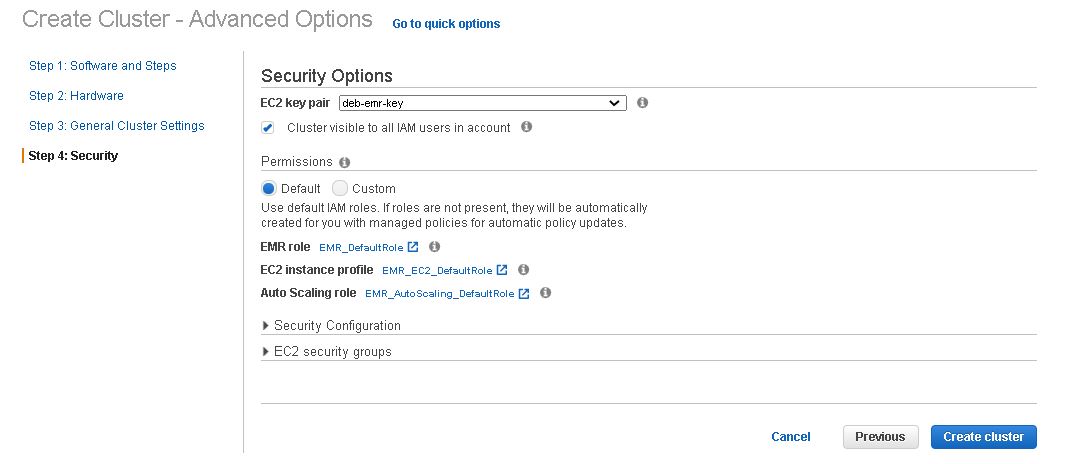
9. Create EMR Cluster using EC2 key
10. Create Notebook in EMR
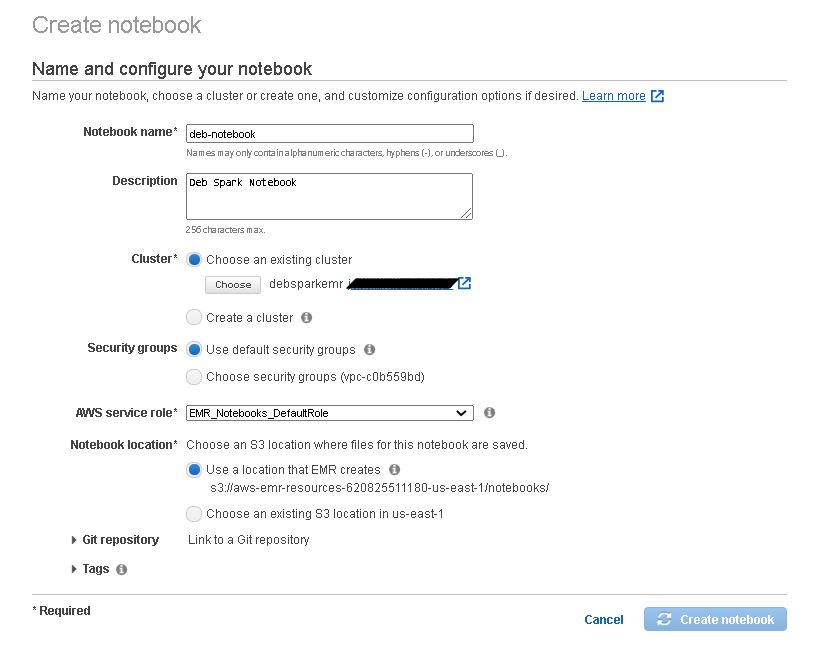
11. Start the Notebook
12. Wait for EMR cluster to start (it takes sometime)

13. Check the status of Notebook

14. Go to JupyterLab and run Spark
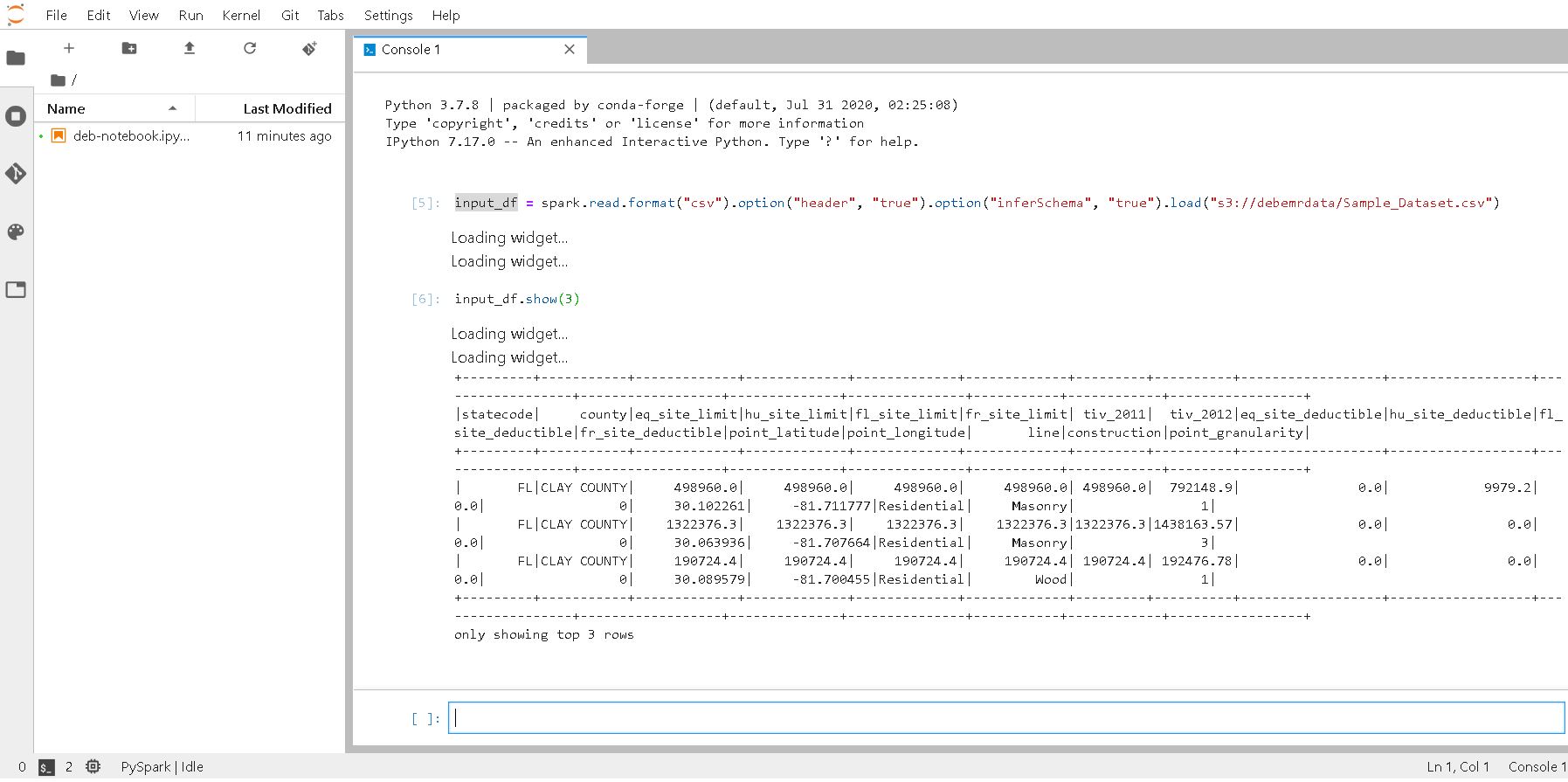
Spark is up and running on EMR Cluster 😊
Note :
-
The steps mentioned above is for POC.
-
In Production or any organization , CloudFormation template and proper IAM roles would be utilized (Concept of least privilege)