Word2Vec Algorithm
About Word2Vec algorithm
- Word2Vec is not a single algorithm
- Word2vec is a group of related models that are used to produce word embedding’s. These models are two-layer neural networks that are trained to reconstruct linguistic contexts of words.
- Word2vec takes large corpus of text as its input and produces a vector-space, with each unique word in the corpus being assigned a corresponding vector in the space.
- Word2Vec can utilize either of 2 model architectures –
- CBOW (Continuous Bag of Words)
- Skip Gram
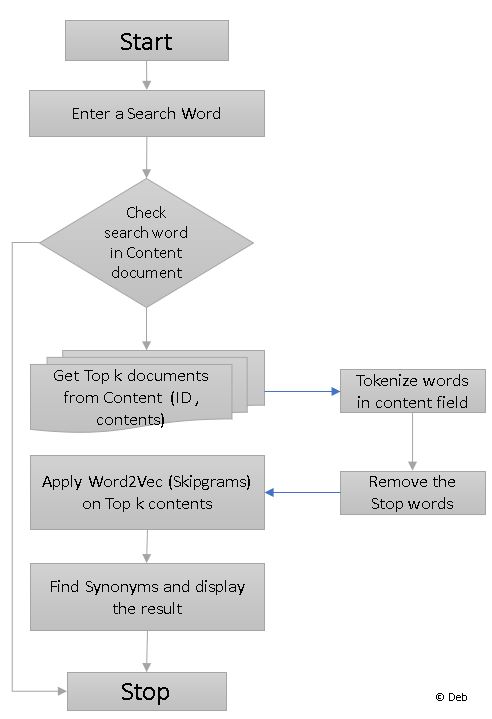
CBOW (Continuous Bag of Words)
The input to the model could be wi−2,wi−1,wi+1,wi+2wi−2,wi−1,wi+1,wi+2, the preceding and following words of the current word we are at. The output of the neural network will be wiwi. Hence you can think of the task as “predicting the word given its context”
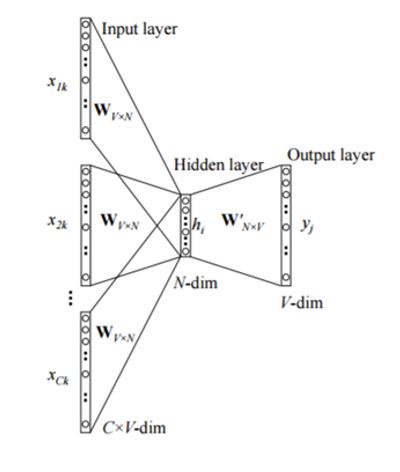
Skip-Grams Algorithm
The input to the model is wiwi, and the output could be wi−1,wi−2,wi+1,wi+2wi−1,wi−2,wi+1,wi+2. So the task here is “predicting the context given a word”. Also, the context is not limited to its immediate context, training instances can be created by skipping a constant number of words in its context, so for example, wi−3,wi−4,wi+3,wi+4wi−3,wi−4,wi+3,wi+4, hence the name skip-gram.
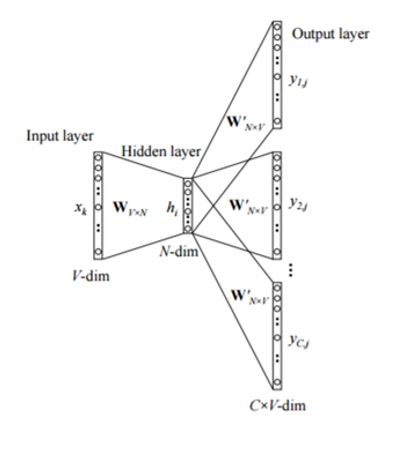
Use-case : Predicting context of search word from SOLR Documents using Word2Vec