Bagging & Boosting
In my last tech blog, I discussed on Decision trees and Random Forrest. So I thought of articulating on Gradient Boosting model and XgBoost. But before these algorithms , its important to understand 2 basic concepts :
- Bagging (Bootstrap Aggregation)
- Boosting
Bagging (Bootstrap Aggregation)
Bootstrapping is a process of creating random samples with replacement for estimating sample statistics. With replacement means , the sample might have duplicated values from the original set.
For example:
Sample S = {10,23,12,11,34,11,1,4,2,14}
Bootstrap sample 1: {10, 23, 11, 4, 2, 14, 11}
Bootstrap sample 2 {23, 10, 12, 11, 14, 2, 14} – 14 is duplicate (which means with replacement in bootstrap sample set)
Bootstrap sample n : {10, 1, 2, 2, 14, 1, 23}
Reason to create BootStrap samples
Once bootstrap samples are created, model classifier is used for training or building a model and then selecting model based on popularity votes.
In case of a classification model, a label with maximum votes will assigned to the observations.
In case of a regression model - average value is used.
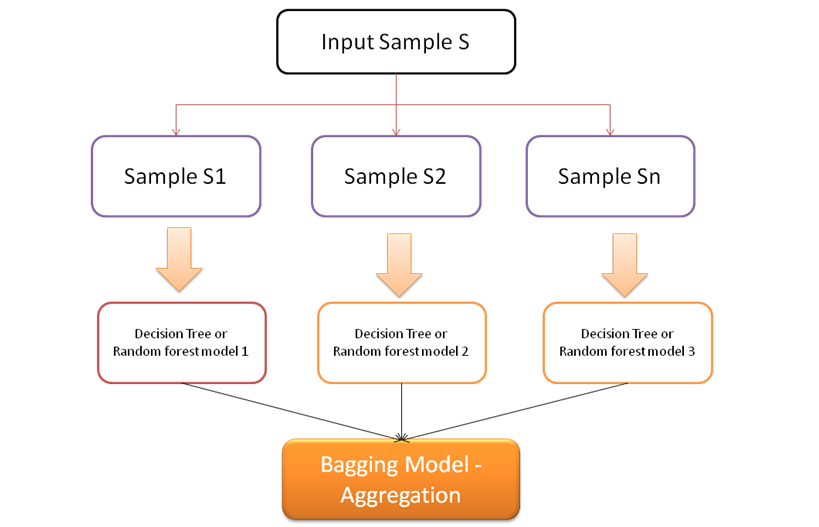
Bagging is an ensembling process – where a model is trained on each of the bootstrap samples and the final model is an aggregated models of the all sample models. Refer to below diagram to understand the Bagging process
Sample Code in Python for Bagging
from random import seed
from random import random
from random import randrange
# Create a random subsample from the dataset with replacement
def subsample(dataset, ratio=1.0):
sample = list()
n_sample = round(len(dataset) * ratio)
while len(sample) < n_sample:
index = randrange(len(dataset))
sample.append(dataset[index])
return sample
# Calculate the mean of a list of numbers
def mean(numbers):
return sum(numbers) / float(len(numbers))
seed(1)
# True mean
dataset = [[randrange(10)] for i in range(20)]
print('True Mean: %.3f' % mean([row[0] for row in dataset]))
# Estimated means
ratio = 0.10
for size in [1, 10, 100]:
sample_means = list()
for i in range(size):
sample = subsample(dataset, ratio)
sample_mean = mean([row[0] for row in sample])
sample_means.append(sample_mean)
print('Samples=%d, Estimated Mean: %.3f' % (size, mean(sample_means)))
Boosting
In layman’s term , it is a process to convert the weak learners to strong learners
Consider our life where we develop life skills by learning from our mistakes, we can train our model to learn from the errors predicted and improvise the model’s prediction .
- Step 1: The base learner takes all the distributions and assign equal weight or attention to each observation.
- Step 2: If there is any prediction error caused by first base learning algorithm, then we pay higher attention to observations having prediction error. Then, we apply the next base learning algorithm.
- Step 3: Iterate Step 2 till the limit of base learning algorithm is reached or higher accuracy is achieved.
Finally, it combines the outputs from weak learner and creates a strong learner which eventually improves the prediction power of the model.
Types of Boosting algorithms
- Ada-Boost
- Gradient Boosting algorithm
- XgBoost (eXtreme Gradient Boosting)
Source
- https://web.stanford.edu/class/stats202/content/lec20.pdf
- https://www.analyticsvidhya.com/blog/2015/11/quick-introduction-boosting-algorithms-machine-learning/
- https://medium.com/analytics-vidhya/boosting-bagging-and-stacking-a-comparative-analysis-e6b213d416b9
- https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
- https://cse.iitk.ac.in/users/piyush/courses/ml_autumn16/771A_lec21_slides.pdf
- https://medium.com/greyatom/a-quick-guide-to-boosting-in-ml-acf7c1585cb5
- https://machinelearningmastery.com/implement-bagging-scratch-python/
- https://machinelearningmastery.com/ensemble-machine-learning-algorithms-python-scikit-learn/