Basic code : Spark streaming
Spark Streaming
DStreams (Discretized Streams)
- It is an abstraction provided by Spark streaming
- It is basically represents series of RDD
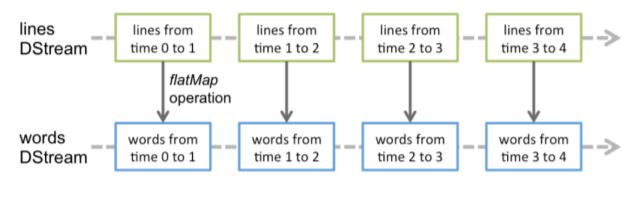
Directory monitoring (dataDirectory) is described here
Window Operations
Spark provides window operation which helps to perform transformation on sliding window
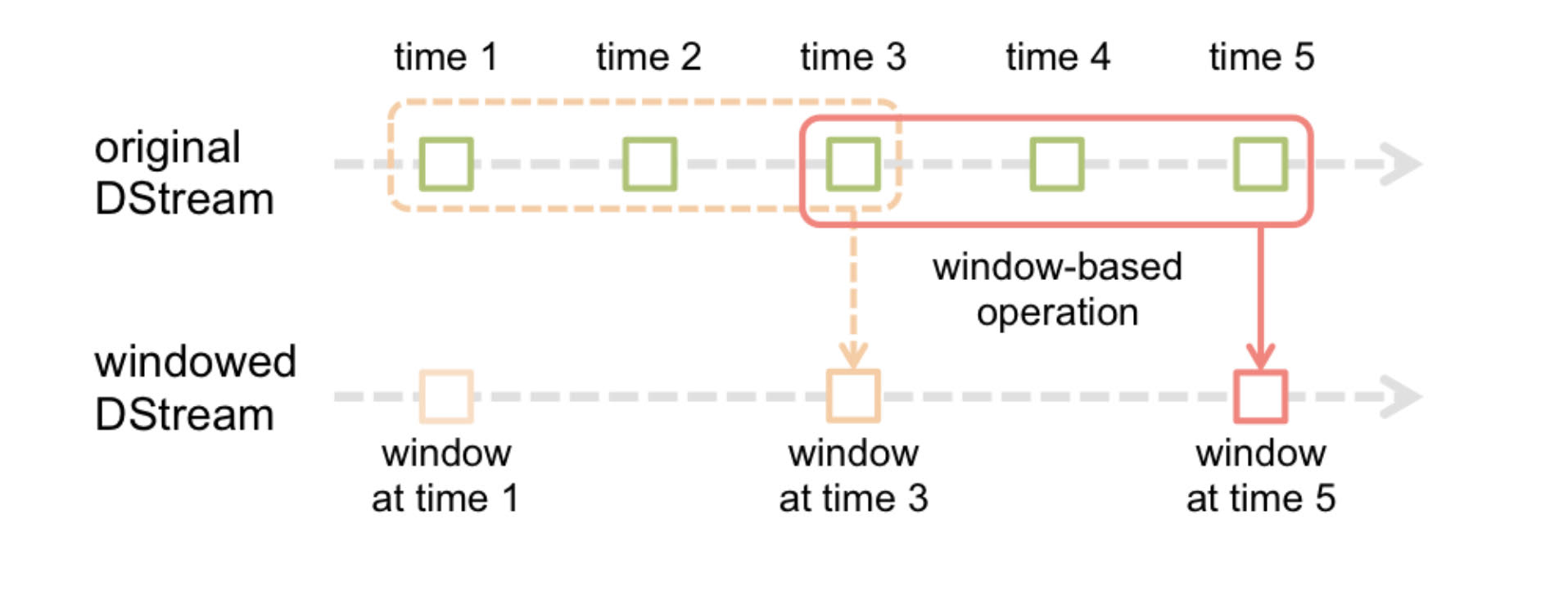
- Window length - The duration of the window
- Sliding interval - The interval at which the window operation is performed
Example of window operation
# Reduce last 30 seconds of data, every 10 seconds
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
Checkpointing
2 types of checkpoints in Spark streaming
-
Metadata checkpointing : Saving information defining the streaming computation to fault-tolerant storage like HDFS. Required to recover from failure of the node running the driver of the streaming application Metadata checkpointing -> recovery from driver failures
-
Data checkpointing : Saving generated RDDs to reliable storage like HDFS. Necessary during stateful transformation where previous batch information (RDD) is important. Data checkpointing -> Necessary for Stateful transformation scenario
Example Spark streaming code (from Apache site)
A simple code to read words in stream and count number of words.
Save the code for word count and run producer with netcat command
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("Word Count") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
For Unix users
nc -lk 9999
For Windows , install nmap from here
ncat.exe -lk 9999
Open another CMD (in Windows) or Terminal (in Linux/Mac) and the run the code to see the result
spark-submit sparkstream.py localhost 9999
Pic / documentation credits : Apache Spark