Activation function
In a neural network, an activation function normalizes the input and produces an output which is then passed forward into the subsequent layer.
Why use Activation function ?
It is used to determine the output of neural network like yes or no. It maps the resulting values in between 0 to 1 or -1 to 1 etc.
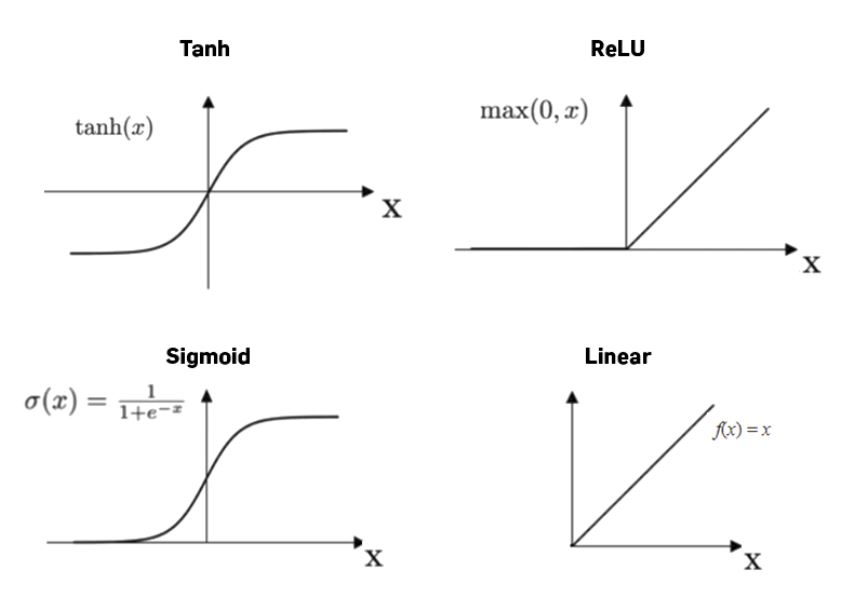
1 . Linear Activation function
- It cannot do back propagation
- No layer and not useful in real-world scenarios
- Equation : f(x) = x
- Range : (-infinity to infinity)
2. Sigmoid function
- Reason to use Sigmoid function : It exists between (0 to 1). Therefore, it is especially used for models where we have to predict the probability as an output.Since probability of anything exists only between the range of 0 and 1, sigmoid is the right choice.
- The function is differentiable.That means, we can find the slope of the sigmoid curve at any two points
3. Tanh or hyperbolic tangent Activation Function
- tanh is also like logistic sigmoid but better. The range of the tanh function is from (-1 to 1). tanh is also sigmoidal (s - shaped).
- The function is differentiable.That means, we can find the slope of the sigmoid curve at any two points
- The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph
- Both tanh and logistic sigmoid activation functions are used in feed-forward nets.
- Range : (-1 to 1)
4 . ReLU
- It stands for Rectified Linear Unit
- Most popular one
- Easy and fast to compute
- Dying ReLU problem : When we have input as 0 or -ve values , which brings linear function in place . This in turn introduces its problem
- Range: [ 0 to infinity)
5. Leaky ReLU
- It solves the dying ReLU problem
- It solves by introducing a -ve slope below 0
We have Parameter ReLU (PReLU) which is same as Leaky ReLU but slope in -ve part is learned by backpropagation
6. Other Activation function
- ELU : Exponential Linear Unit
- SWISH : From Google , includes 40+ layers
- MaxOut : ReLU is special case of maxout. Not practical solution (doubles parameters)
- SoftMax : Used for multiple classification.
Choose Activation function (Suggestion)
- Multiple classification : SoftMax
- RNN : TanH
- For everything else
- Start with ReLU
- Next , try with Leaky ReLU
- Last resort for PReLU SWiSH can be utilized for really deep network
Cheatsheet
Soure : Link is here
