Design Cloud Storage App
Definition
A platform to upload , view , search and share huge files efficiently (Cloud STorage)
Requirements
Functional Requirement
- Users should be able to upload and download their files/photos from any device (huge files)
- Users should be able to share files or folders with other users.
- Automatic synchronization between devices
- Support ACID
- Platform must support offline editing. Users should be able to add/delete/modify files while offline, and as soon as they come online, all their changes should be synced to the remote servers and other online devices.
Non-Functional Requirement
- Low latency : System should provide near real time data upload
- Consistency : System should provide same file to users in all devices
- Available : System must be highly avialable
- Reliable : System should not lose data
Capacity Management
Space estimation
- Total users : 500 M
- Active users : 100 M (daily)
- Avg file size : 100 KB
- Say user as 200 files ,then total number of files 10 Billion
- Total space requirement : 100 KB (file size) * 10 Billion files = 10 PB
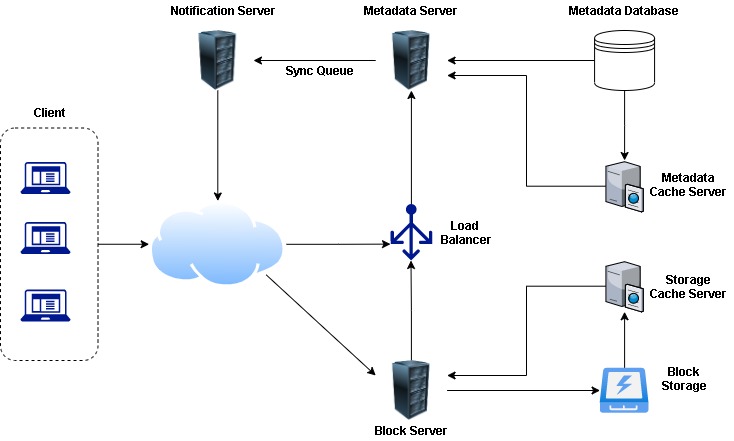
Component Design
5 major components
- Client
- Metadata database
- Synchronization service
- Message queue service
- Cloud Storage
Client
Major tasks of client
- Upload and download files.
- Detect file changes in the workspace folder and syncs all files/folders with the remote Cloud Storage.
- Handle conflicts due to offline or concurrent updates.
Various parts of client :
- Internal metadata database : Keep track of files , chunks , versions , location in file system , etc
- Chunker : Split large files into small chunks and also will be responsible to merge the chunks appropriately
- Watcher : It will monitor and detect changes in workspace (like new file,delete or update) and notify the indexer
- Indexer : It will process the events from Watcher and update the internal metadata database with modifed chunks and communicate with Sync service to other clients about the changes.
Also read about HTTP long polling
Long Polling helps in efficiently listening to changes happening with other clients.
Metdatadata Database
Choice of Databases :
- Relational database : Supports ACID and no extra code for Sync service . But will have to comprise scalability , flexibility and performance
- NoSQL : Much better scalability , flexibility and performance as compared to relational. But most of widely used NoSQL does not support all ACID properties
My recommendation would be NoSQL as we can write code Sync process but wont be able to comprise on scalability , flexibility and performance provided by NoSQL over RDBMS
Information in Metadata Database :
- Chunks
- Files
- User
- Devices
- Workspace (sync folders)
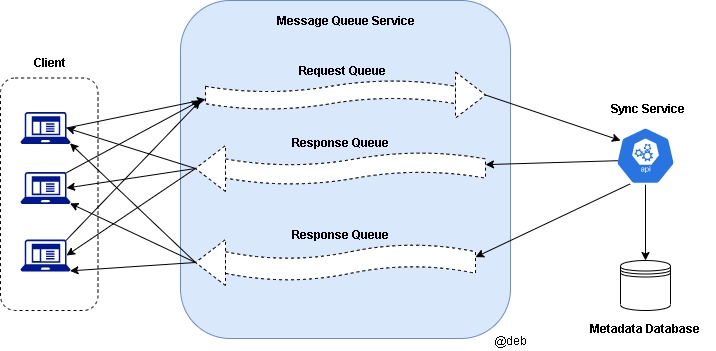
Synchronization Service
- Critical role in managing metadata and synchronizing users files
- It needs to employ a differencing algorithm to reduce the amount of the data that needs to be synchronized. Instead of transmitting entire files from clients to the server or vice versa, we can just transmit the difference between two versions of a file. Therefore, a delta or difference is transmitted.
- Need to utilize communication Middleware between clients and Sync service in order to provide efficient and scalable sync protocol.
Message queue Service
- A scalable message queue that supports asynchronous message-based communication between clients and the Synchronization Service
- It must be loosely coupled message-based communication between distributed components of the system.
- It should be reliable
- It should be able to efficiently store any number of messages in a highly available
Cloud Storage
- It stores of chunks of data uploaded by users
- Metadata and data storage are separate - it enables us to use any storage layer (cloud or onprem)
File Processing
Scenario
When Client A updates a file that is shared with Client B and C, so they should receive the update too.
1. Client A uploads chunks to cloud storage.
2. Client A updates metadata and commits changes.
3. Client A gets confirmation and notifications are sent to Clients B and C about the changes.
4. Client B and C receive metadata changes and download updated chunks.
Data Deduplication
For each new incoming chunk, we can calculate a hash of it and compare that hash with all the hashes of the existing chunks to see if we already have the same chunk present in our storage.
2 ways of de-duplication process:
-
Post process dueduplication (Deduplication post storage)
- Advantage: Clients need not wait while storing data
- Disadvantage : High space consumption for short period of time
-
In-line deduplication (Real-time deduplication process)
- Advantage : Efficient use of space
- Disadvantage : Clients need to wait to first perform deduplication process
Metadata partitioning
Vertical Partitioning
For example : Store all user related info in 1 database and store files/chunks info into another database
Problems associated with this approach :
- Scalability
- Performance issue (while performing aggregations/joins)
Range based Partitioning
For example : We start saving all files starting with the letter ‘A’ in one partition and those that start with the letter ‘B’ into another partition and so on.
Problem associated with this approach :
- It can lead to unbalanced server . Suppose there 1M+ files starting with letter A,D,S and less than 100 files starting with Q,X,Y,Z - this will lead to uneven distribution.
Hash based Partitioning
For example : We hash of the ‘FileID’ of the File object and determine the partition. Our hashing function will randomly distribute objects into different partitions
It can lead to Overload of parttions which can be solved by Consistent Hashing
Cache & Load Balancer
Read about load balancer from here
Load Balancer
Need to have :
- Between Clients and Block server
- Between Clients and Metadata servers
Round robin approach can be adopted - It has its own adv and disadvantages. As in RR approach , it does not take server load into consideration. We may require new intelligent LB solution that can be replaced periodically depending on server load and adjust traffic based on the load.
Cache
We can cache for hot files/chunks which can be used to store whole chunks before hitting block storage Read about cache from here
More readings
Encourage to subscribe & go through course in more details from Educative.io - here