AWS : Redshift + S3
Brief on Redshift
A few key features of Redshift
- Column Oriented Datatase : Data is stored in columnar format which gives an advantage of more speed during analytical or data access process.
- Fault tolerance : During the failure times, Redshift autmatically replicates data to healthy nodes
- Concurency limits : Redshift maintains concurency limits which ensures the adeuqate compute resources are available to all users.
- Massively parallel processing : In Redshift , a large processsing job is divided into smaller jobs which performs the computation in sequential manner . This helps to increase the speed of completion of task.
- End-to-end data encryption : Encryption is highly customizable and robust in Redshift.
- Network isolation : Administrators can choose to isolate the network within Redshift (in an org) using Amazon VPC
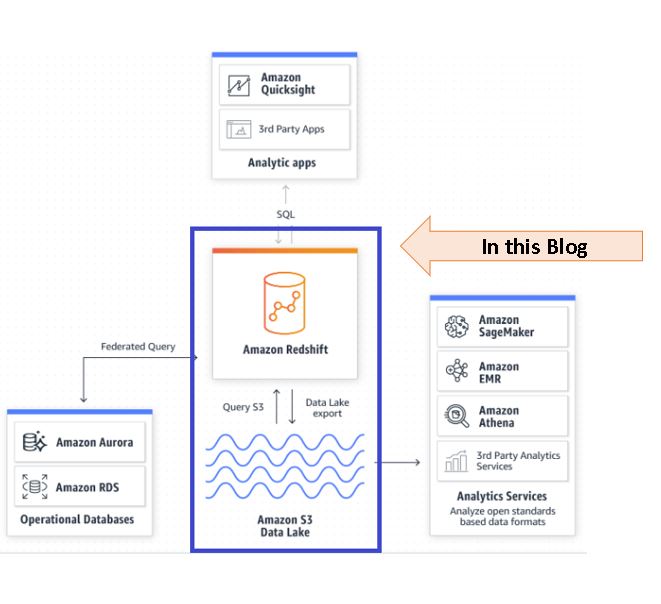
Redshift plays important role on creating Data Lake in Cloud
Image credit to AWS Blog
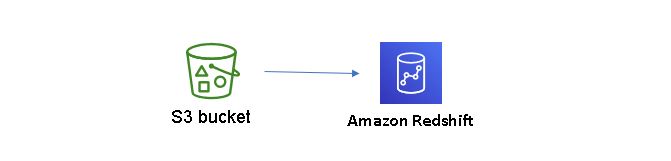
8 Simple steps to load data from S3 to Redshift
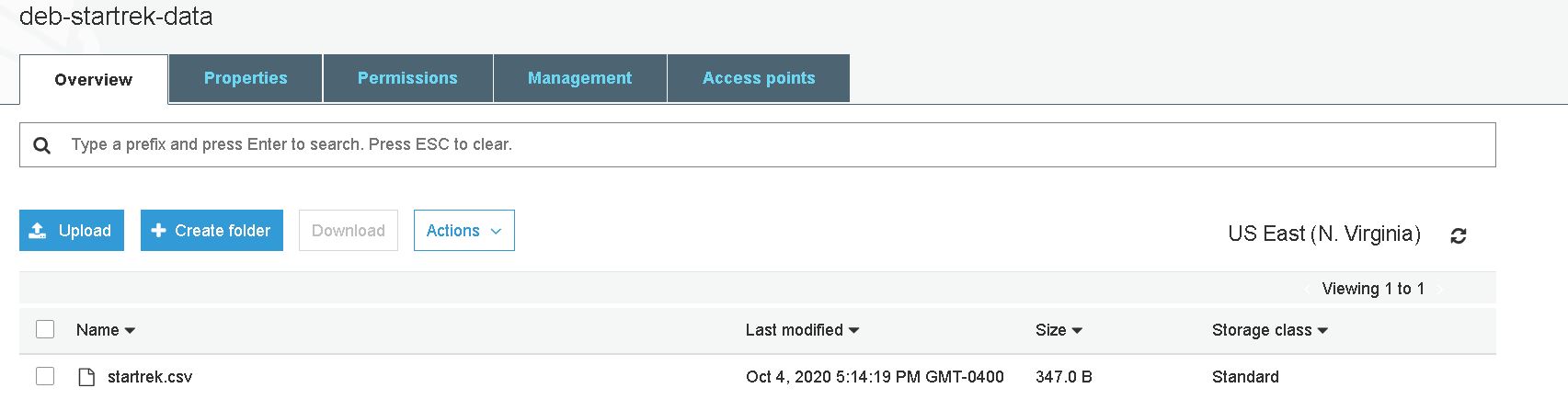
1. Create dataset and upload in S3
2. Create Role for Redshift
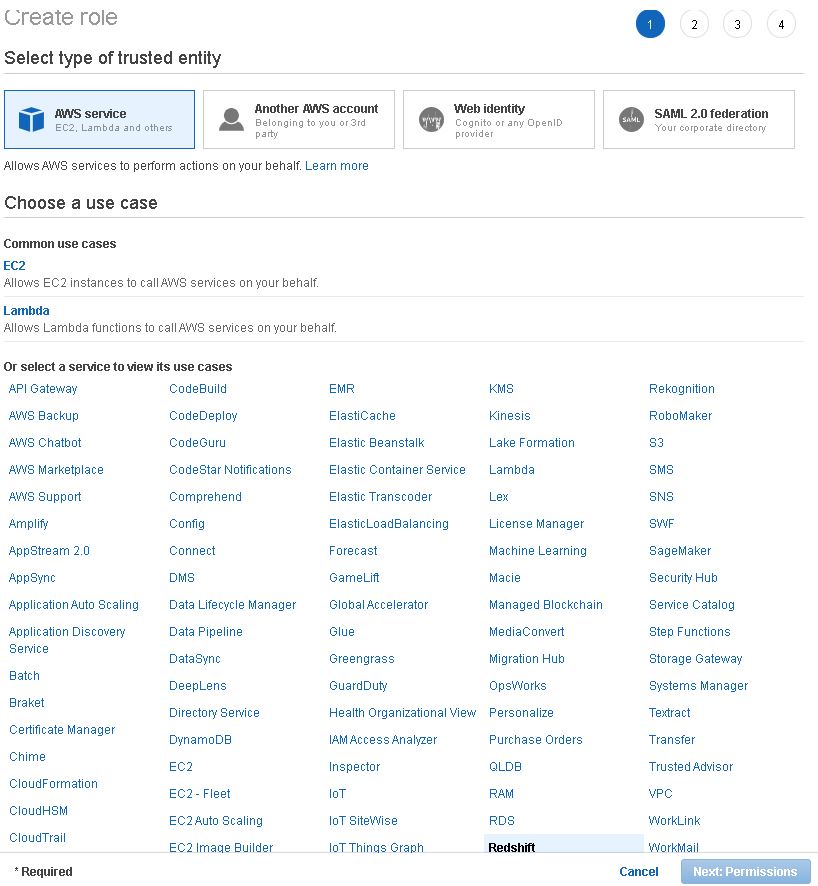
3. Create role with AWS S3 Full Access
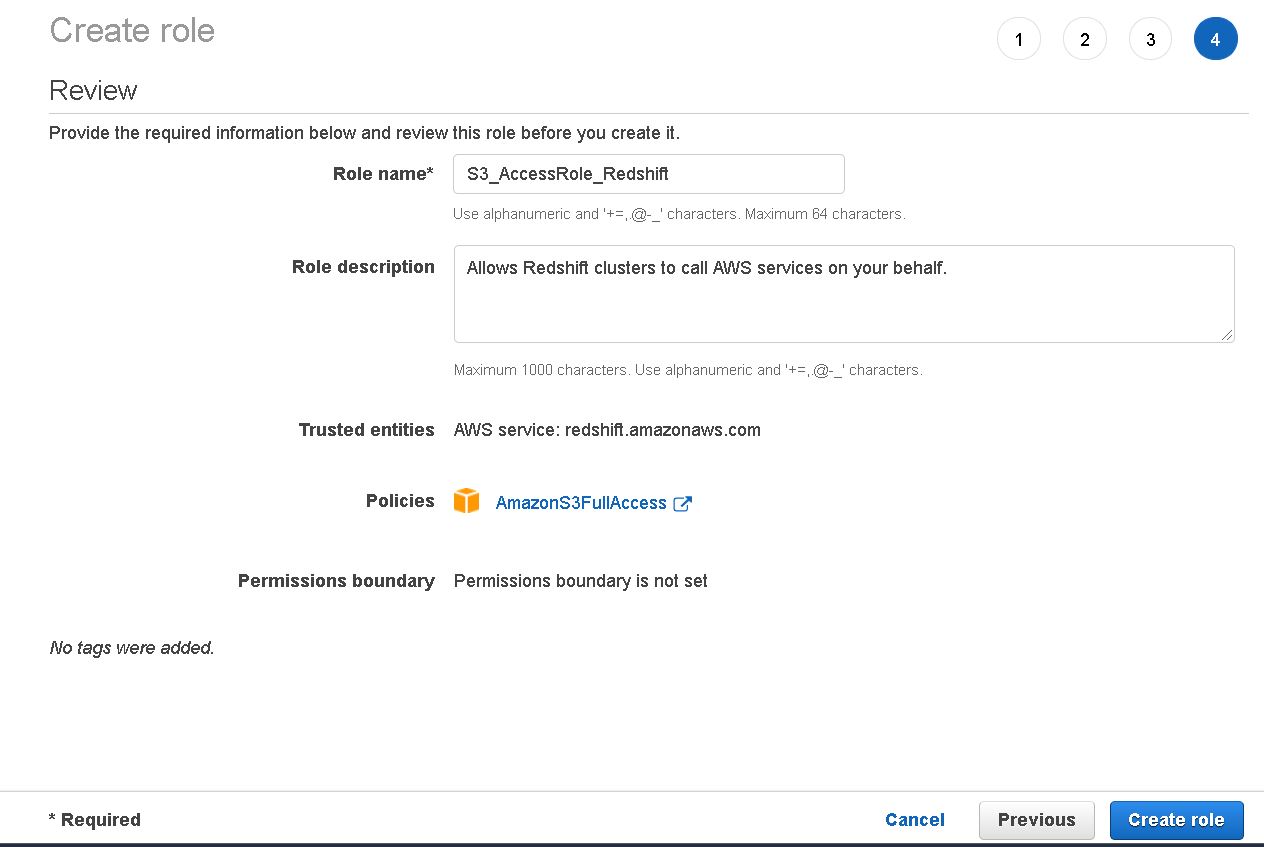
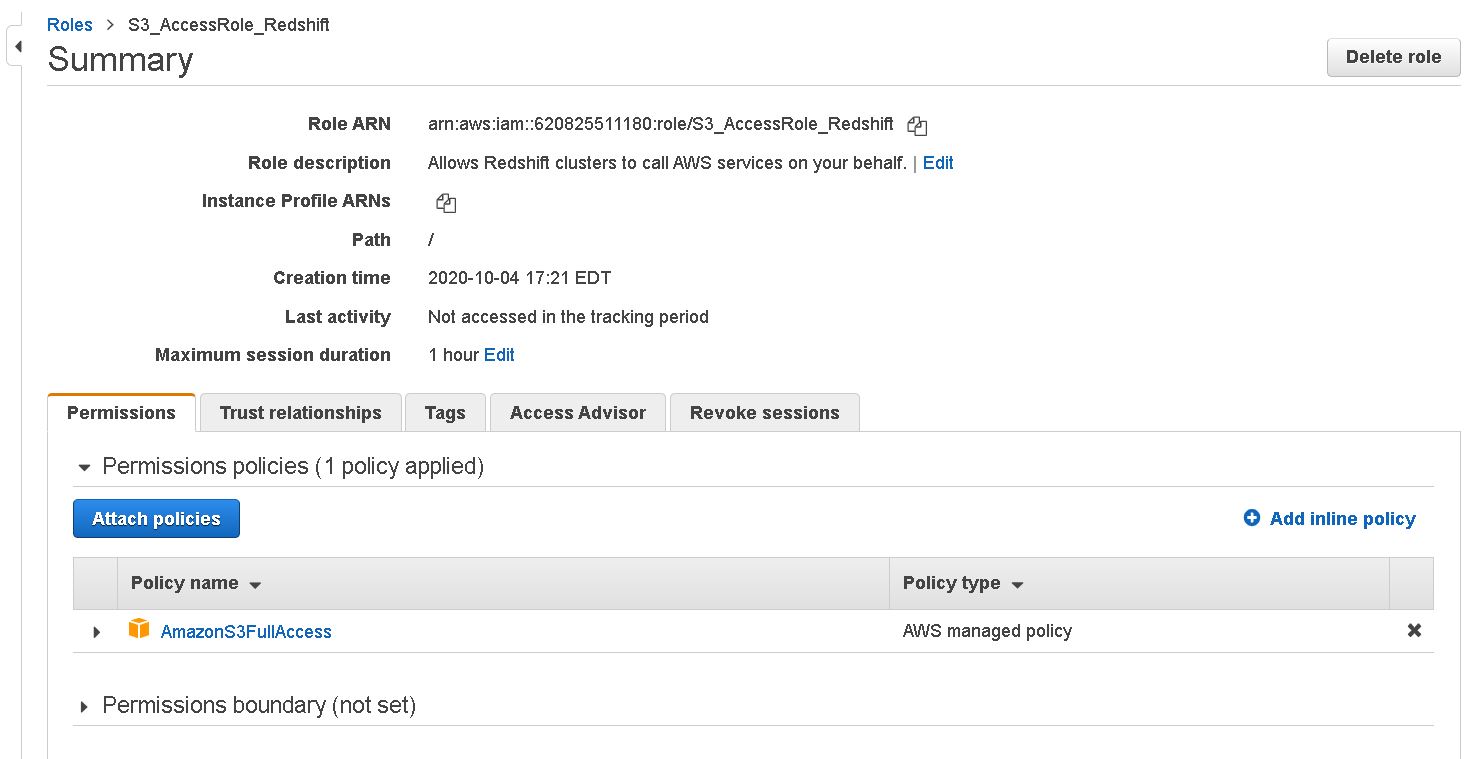
4. Get the IAM role which will be required to Copy command
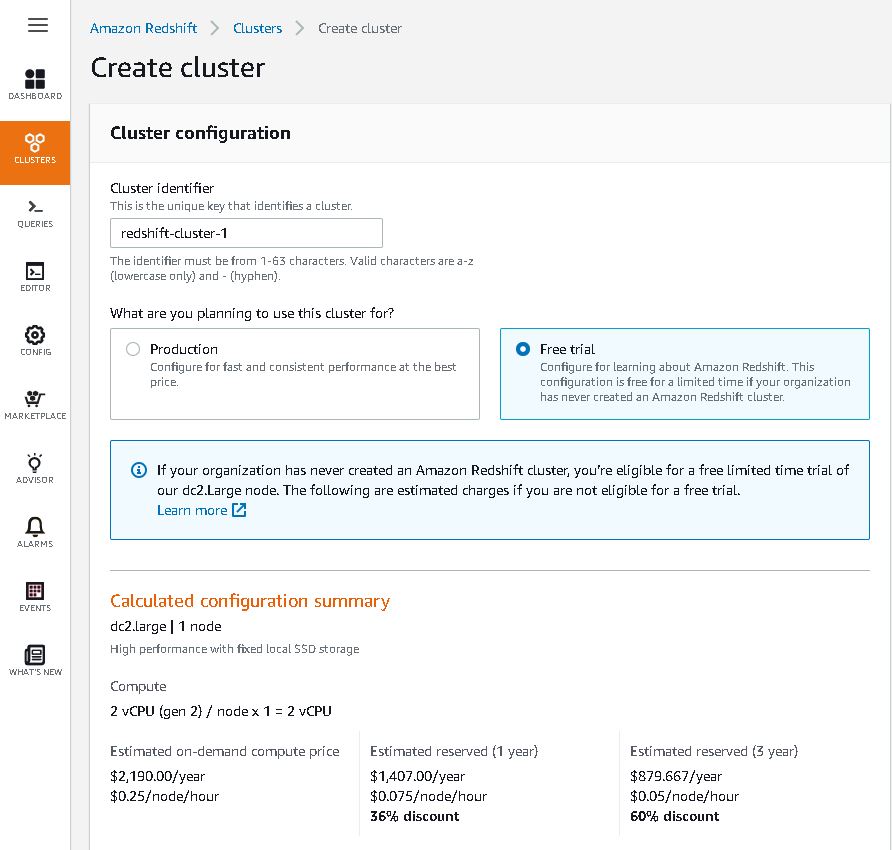
5. Go to Redshift and create Cluster (Try Free trail for demo)
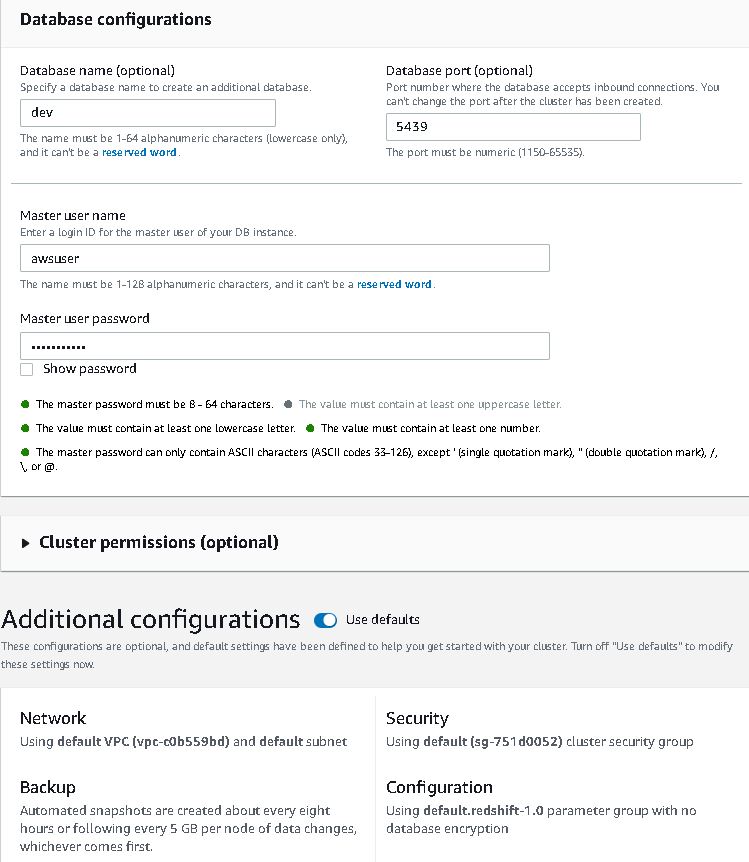
6. Setup the Redshift cluster with user,database and credentials
7. Cluster create process runs
It takes 4-5 minutes

8. Create table say employees of Startrek
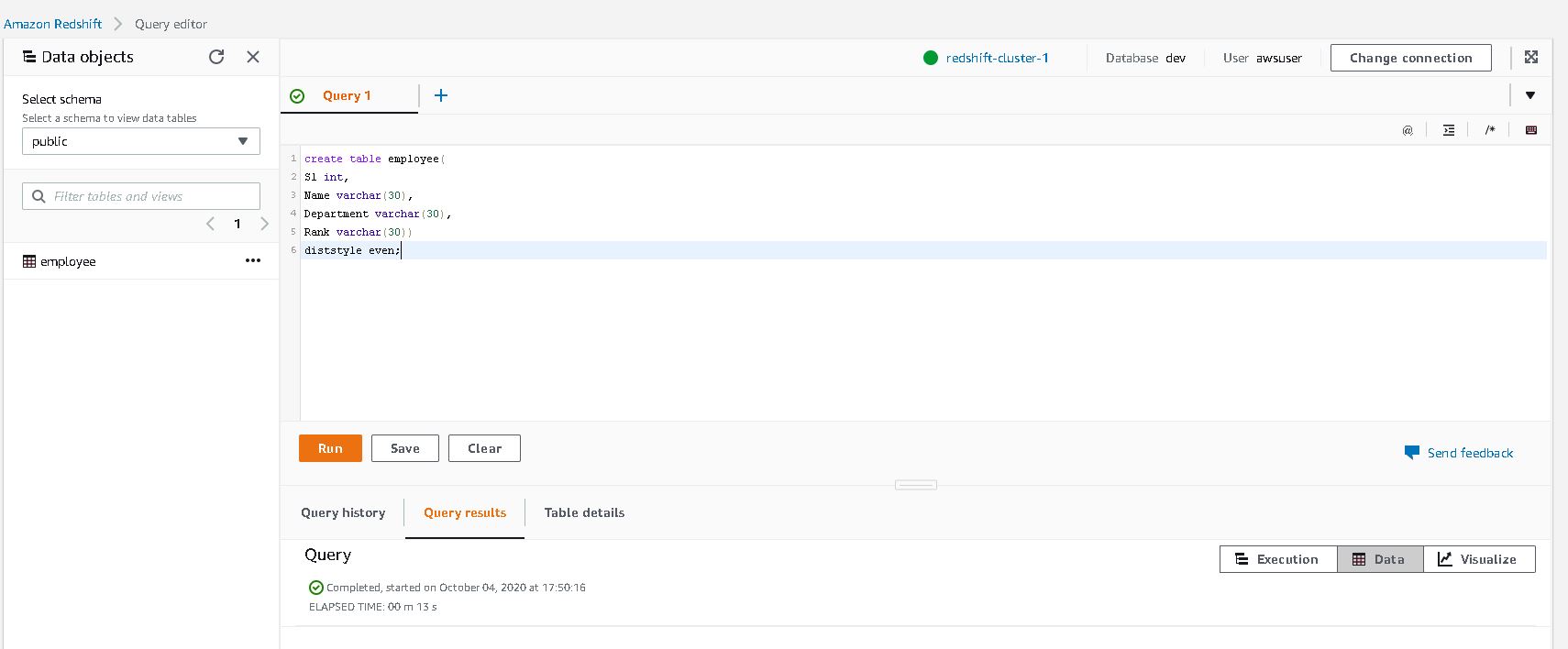
9. Copy the contents of S3 data into the table
copy employee (Sl,Name,Department,Rank)
from 's3://deb-startrek-data/'
iam_role 'arn:aws:iam::620825511180:role/S3_AccessRole_Redshift'
csv
IGNOREHEADER 1;
select * from employee;
Query Editor to paste the above command
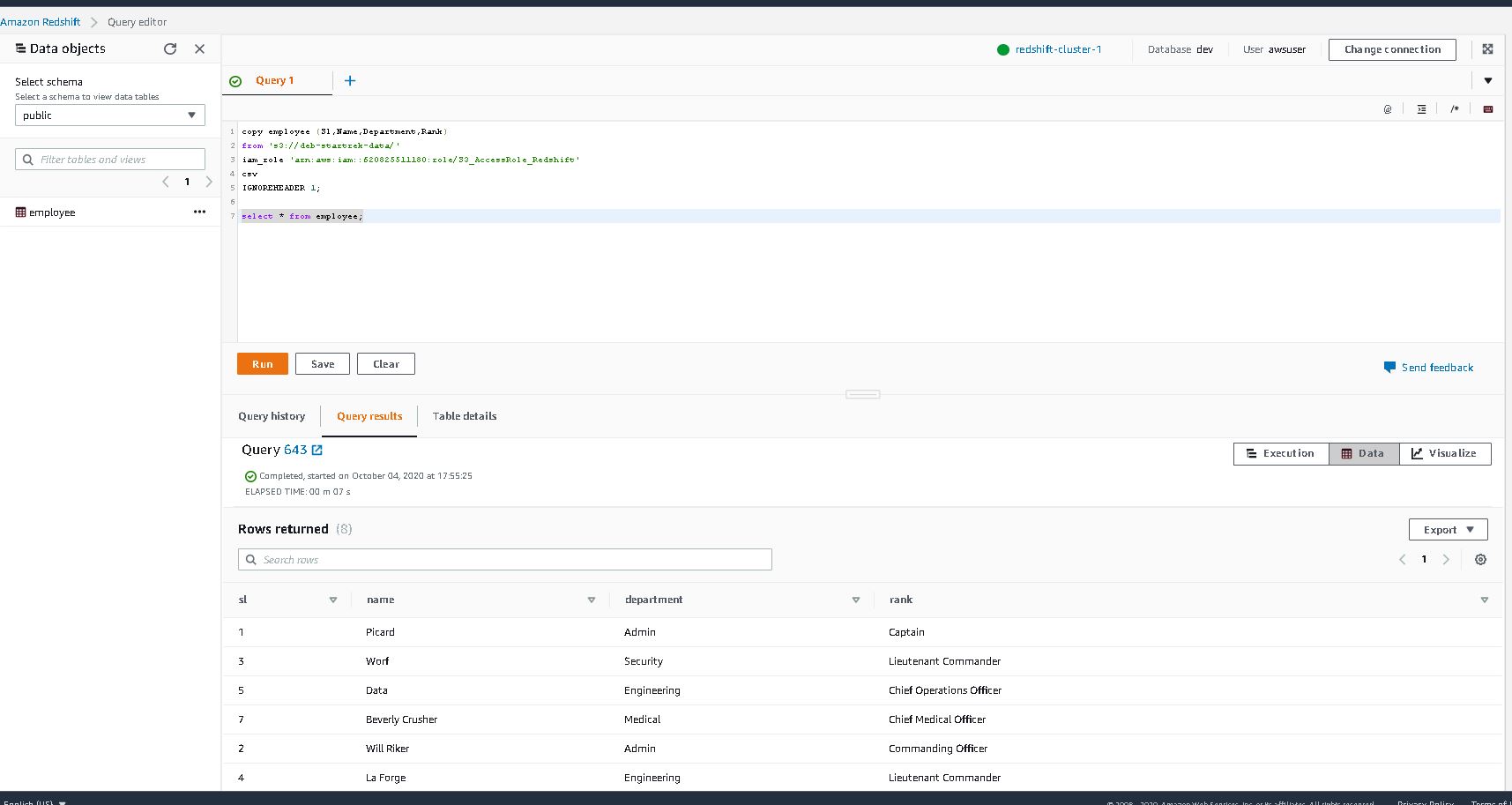
You have the data in Redshift from S3 !!
Note :
-
The steps mentioned above is for POC.
-
In Production or any organization , CloudFormation template and proper IAM roles would be utilized (Concept of least privilege)