Basic definition of Spark
Install Spark
For Windows : Please follow this site
Basics of Spark Flow
Run Spark application -> Driver program starts -> Main function starts ->
SparkContext gets initiated -> Driver program runs the operations inside the executors on worker nodes.
SparkContext uses Py4J to launch a JVM and creates a JavaSparkContext. By default, PySpark has SparkContext available as ‘sc’, so creating a new SparkContext won’t work.
Serialization and Deserialization
Serialization is a mechanism of converting the state of an object into a byte stream. Deserialization is the reverse process where the byte stream is used to recreate the actual Java object in memory.
- Serialization : Java object -> Byte stream
- Deserialization : Byte stream -> Java object
We need serialization because the hard disk or network infrastructure are hardware component and we cannot send java objects because it understands just bytes :)
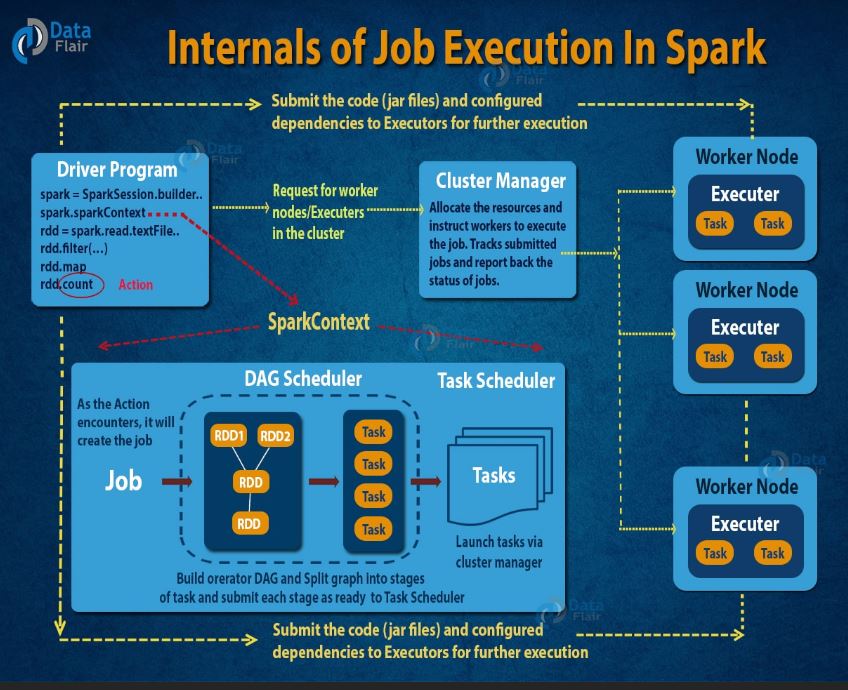
Execution of Spark Job
Excellent training from Data Flair
Spark Stages
2 types of Spark Stages
-
ShuffleMapStage : Intermediate stage in physical excution of DAG. In Adaptive Query Planning , it can be considered as final stage as well which can save output map files.
-
ResultStage : Final stage in Spark. It helps in computation of result of an action.
Lazy Execution
Lazy evaluation in Spark means execution of any task wont start start until an action is triggered. Spark has 2 operations
- Transformation
- Action
Transformation is lazy which means operation wont be performed until an action is triggered.
Major Advantage of Lazy execution
- Reduces number of queries - Increase optimization
- Increases speed of the application - less trips between cluster and driver

RDD vs Data frame vs Data Set
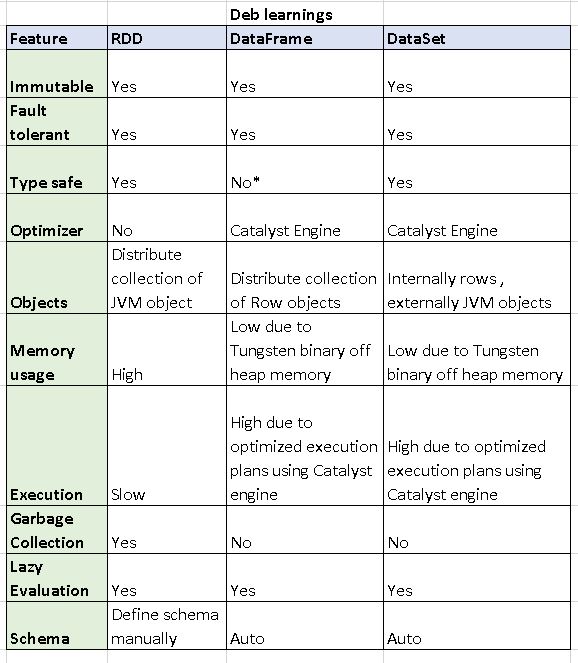
*Type safe
- RDDs and Datasets are type safe means that compiler know the Columns and it’s data type of the Column
- In Dataframe, it will always return the result as an Array of Rows not as Long, String data type
Broadcast and Accumulators
Spark provides Shared variables which are broadcast and accumulator variables.
Broadcast variables It allows users to keep a copy of variable (which can consist of large dataset) cached in each machine which can be utilized during task execution. It saves the communication cost and thus increases speed of application.
Accumulators They can be used to implement counters (as in MapReduce) or sums. Its only “added” to through an associative and commutative operation
Cache in Spark
Cache is an important factor in Spark application. Cache the dataframe whenever user feels the data is going to be used several times. It helps to improve the performance of application and also create checkpoints in application
Types of Storage level in Spark
- DISK_ONLY: Persist data on disk only in serialized format.
- MEMORY_ONLY: Persist data in memory only in deserialized format (DEFAULT)
- MEMORY_AND_DISK: Persist data in memory and if enough memory is not available evicted blocks will be stored on disk.
- OFF_HEAP : Persist data in off-heap memory.
Note - cache() in spark is lazily evaluated. Data will be cached when the 1st first action is called.
Spark Narrow vs Wide dependency